I Like RSS
{kind=link}
I first heard about and started using RSS in early 2008, it was a huge deal for me – I’d been going to individual tech sites to consume my news, and had collected a large set of bookmarks. As I browsed the web I’d been dutifully ignoring a little orange icon that would eventually revolutionise the way I read content on the internet.
This post explains RSS for the uninitiated, it talks through the different experiences I’ve had with feed readers over the years, and unashamedly promotes my new side project.
What is RSS?
I’m using the term RSS, when what I really mean is a web feed. A web feed is a form of syndication – where content from one website is made available in a machine-readable format so that it can be consumed elsewhere.
So if you have a blog somewhere on the internet, it’s likely that your posts (by default) will be presented as HTML. HTML is amazing, but it’s a format designed to be read by humans. A machine finds HTML much more difficult to understand when it comes to extracting content from a page because there’s a lot of inconsistency in how HTML is written.
For example, my website might have article content in the following markup:
<article class="main-content">
<h1>This is my article</h1>
<p>Published <time datetime="2020-01-26">26th Jan 2020</time></p>
<p> ... </p>
</article>
Whereas someone else’s website might use something more like:
<div class="main-Hi07dOXkA">
<div class="article-hoBuu7MMQ">
<div class="heading-area-kmcsJQLH5">
<div class="heading-cJR9JlGUe">This is my article</div>
<div>Posted January 26th 2020</div>
<div> ... </div>
</div>
</div>
</div>
Web feeds help to make content more portable by being strict about how content is organised. The two most common file formats for web feeds are XML-based, and they are RSS and Atom.
A blog post in an RSS feed looks something like this, and content has to be represented like this otherwise it’s not considered valid RSS:
<item>
<title>This is my article</title>
<description> ... </description>
<link>https://www.example.com/blog/post</link>
<pubDate>Sun, 26 Jan 2020 01:37:00 +0000</pubDate>
...
</item>
These strict formats mean that machines have a much easier time processing content, and that content can be easily consumed by an application called a feed reader, or news aggregator. A feed reader takes a collection of RSS or Atom feeds, curated by you, and presents the content uniformly in a single interface.
So if you’re consuming all your web content via a feed reader, you no longer have to maintain a list of websites to check back on – the process of fetching new content is automated by a machine and you can just enjoy reading it.
Google Reader (2008–2013)
Back in 2008, when I finally tried clicking on one of those orange buttons, a very popular feed reader was owned by Google. It was called Google Reader.

This is what I decided to use to read content, because a feed reader owned by such a large company is probably the most stable and long-lasting choice, right?
I think this was the golden age of my content consumption. Google Reader fit really nicely into my daily workflow, and I knew the program inside out.
Then, in 2013, Google decided to retire the product. It was a bummer.
Google at least let people take some of their data with them, it was possible to export your list of feeds so that you could take them to a different reader. I downloaded my list of feeds and went in search of a new home.
Fever (2013–2016)
After being burned by Google Reader shutting down, I wanted some guaranteed stability. I decided the best way to ensure this would be to pay money for a feed reader. I settled on Fever.
What I loved about Fever at the time is that it learned what content I liked to read and ordered the list of unread items by how much I might enjoy them, it was also self-hosted. The benefits of a self-hosted feed reader are:
- If the software is discontinued, you still have a copy of it and can probably continue running it (at least for a while)
- I can run it on my own server, or on a cloud provider like Heroku. Normally this means I can choose to pay if I want more stability or I can stick with a free tier if that’s all I need for now
- If I have the time and energy, I can make tweaks to the software to make it better suit my needs
Despite all this my reading did tail off, and Fever failed to enter my daily workflow in the same way that Google Reader did, despite having paid $30 for it. My use of it had already dropped to nothing by 2016, and Fever’s maintainer discontinuing the project was the final nail in the coffin.
Stringer (2016–2017)
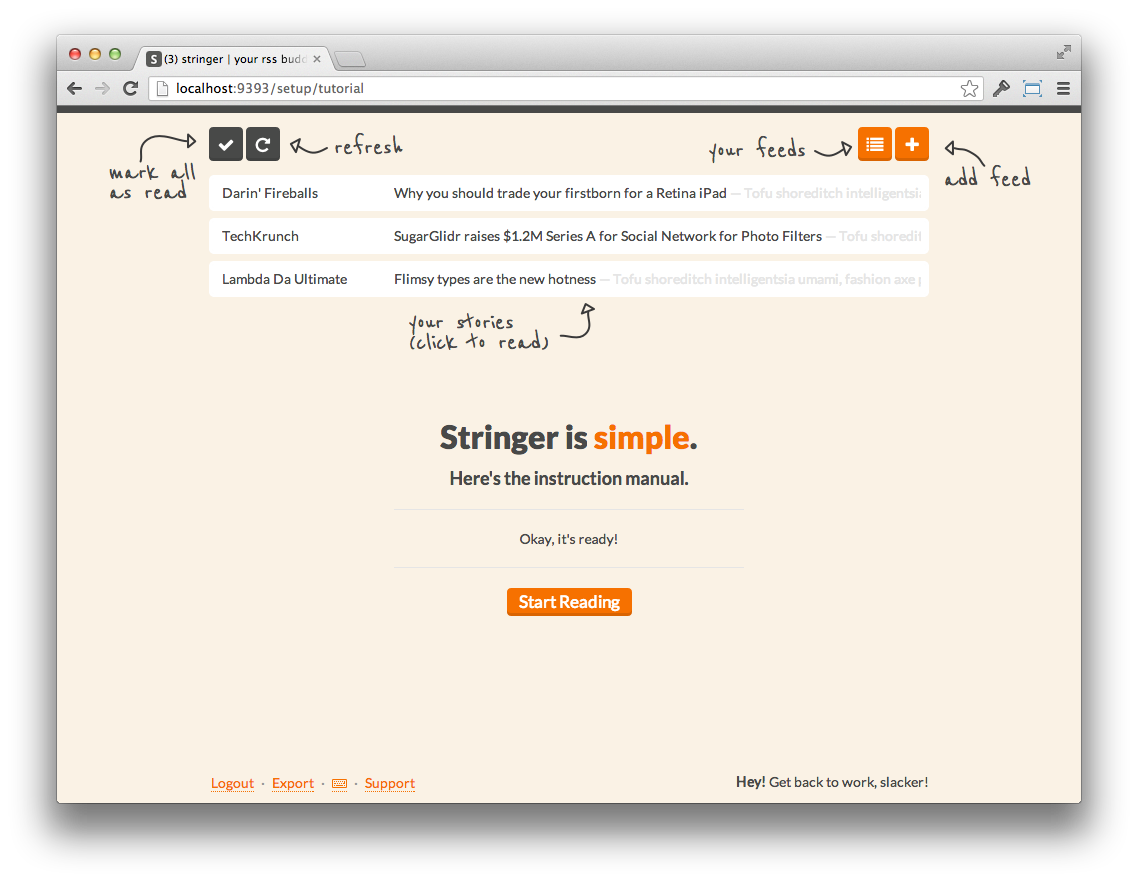
After Fever, I thought maybe I could kickstart my reading again with a shiny new interface. I got rid of most of my feeds as the sheer volume of content had become too much for me and started fresh with Stringer.
Stringer was also self-hosted, and I enjoyed the simplicity of it – a minimally styled single-column list of content was all I really needed, especially as the number of feeds I was subscribed to was at an all time low. I think my consistent reading lasted a few months at best.
By mid-2017 I was reading next to nothing about tech, and Stringer was abandoned by me. I turned it off without a replacement. When I came back a few years later to have a look at the project, it had been archived on GitHub so that’s yet another dead feed reader.
The Time Between (2017–2019)
I spent a good few years really not reading anything or blogging myself, this coincided with a lull in my side project and open source work, because I’d burned myself out and fallen out of love with tech as an industry. But that’s a story for another day, the gist is I didn’t read anything for a pretty long time.
Feedly (2019–2020)
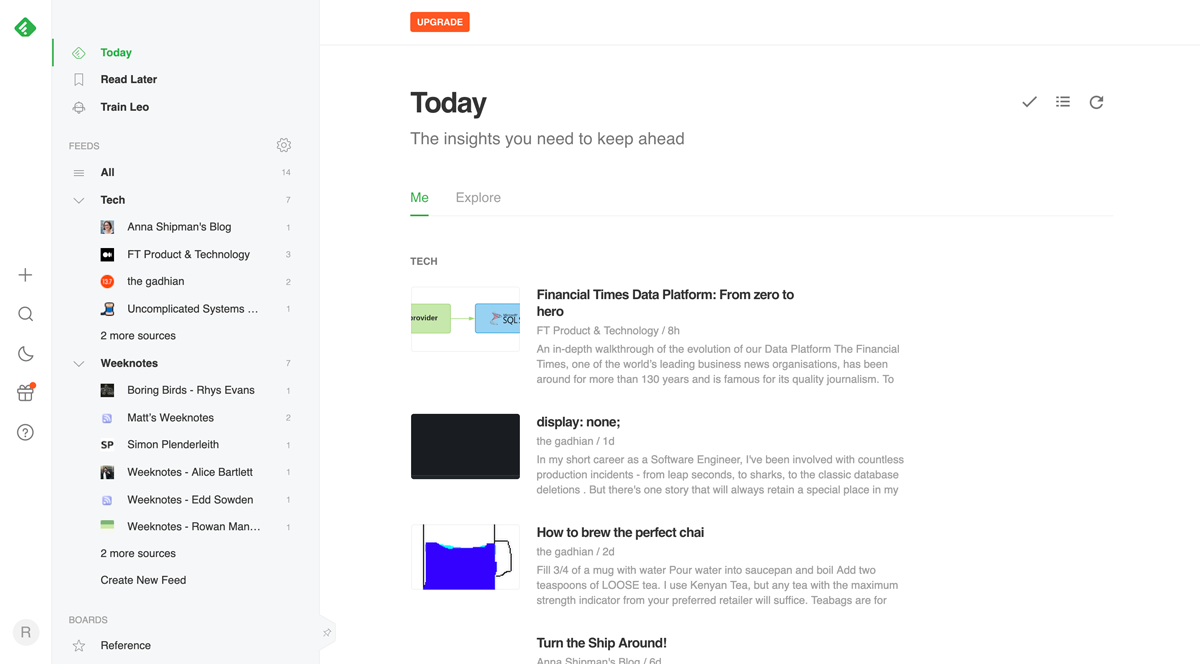
In 2019 I made a conscious effort to read a bit more. I’d been a line manager for a while at this point, and although I’d done some training, I was lacking the reading that had really boosted my early development career. I decided that rather than trying to set up an open source feed reader again, the quickest thing to do would be to use something commercial.
I set up Feedly, intending on upgrading away from their free tier if I liked it.
I didn’t. There’s something about Feedly’s interface I just can’t get behind, there’s noise I don’t need like all the social buttons, as well as recommended content. I also found that the way feeds are managed didn’t gel with how I want to read. Maybe some of these things could be solved by paying for it, but I really don’t like it enough to do that.
Audrey (2020–???)
I didn’t really read a lot through the pandemic, but through October and November my reading increased markedly. Several of my friends and colleagues are publishing Weeknotes, and I was feeling left out. I started publishing my own, and at the same time my reading massively increased. I don’t yet know whether this is sustainable, but I used that and my recent enjoyment of side projects to do something inadvisable.
I built my own feed reader and named it Audrey.
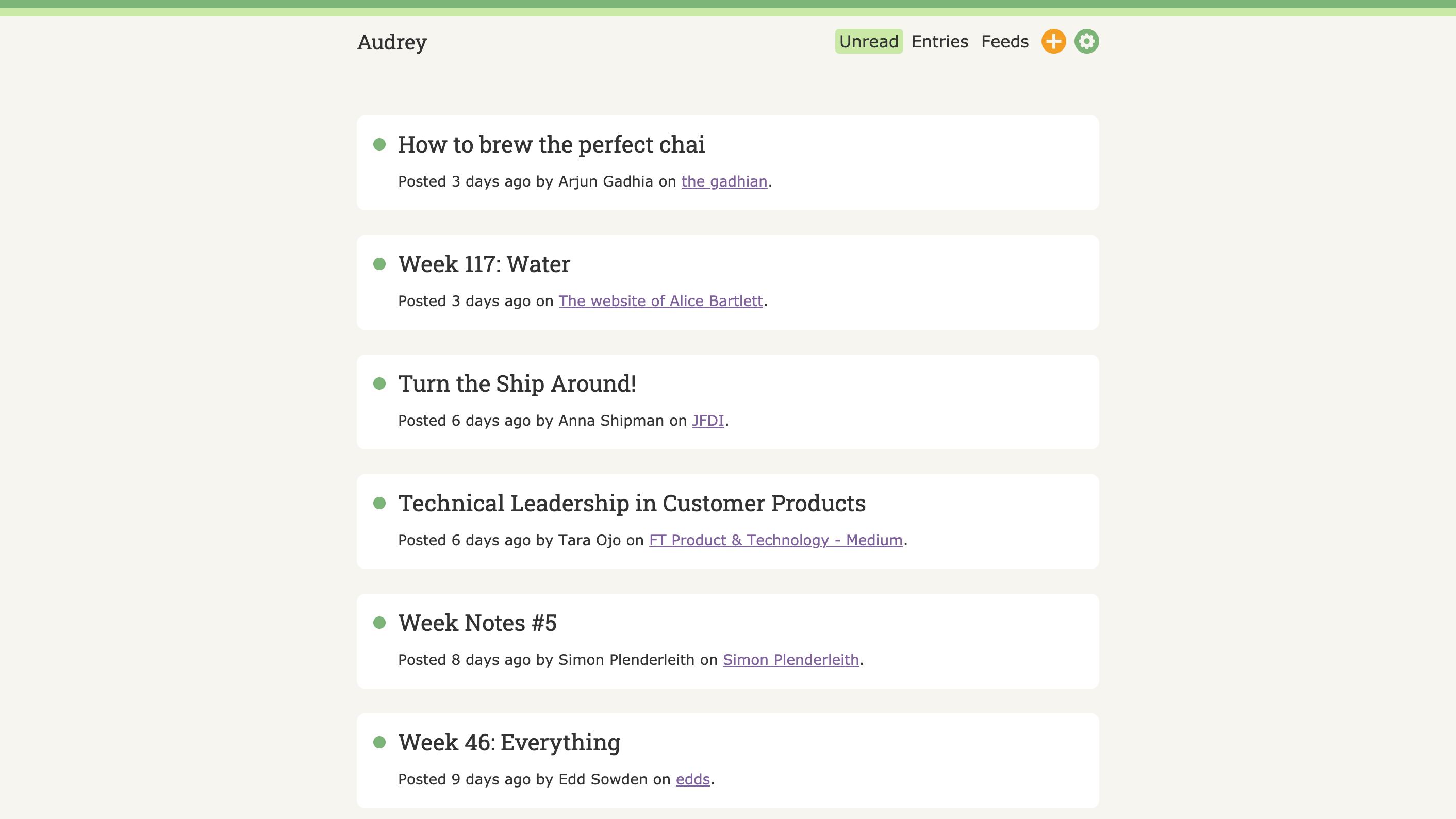
This was a fun project to work on, and regardless of whether I stick with it, for now I have a feed reader that does things exactly the way I want them:
- The interface is simple and minimal
- I can host it wherever I want (it’s on Heroku at the moment)
- There are no algorithms suggesting content to me
- There are no advertisements
- There’s nothing tracking me
- I can add new features as and when I need them
It’s not finished yet, I’m considering it a beta, but it’s stable enough that I’m using it as my every-day feed reader. If you’re interested in a feed reader that meets the above requirements, please give Audrey a go – the docs are pretty great and you can host it for free using MongoDB Atlas and Heroku.
I’d really appreciate bug reports if you find any. Also let me know if you’re interested in a follow-up to this post explaining the architectural decisions I made 🙂